
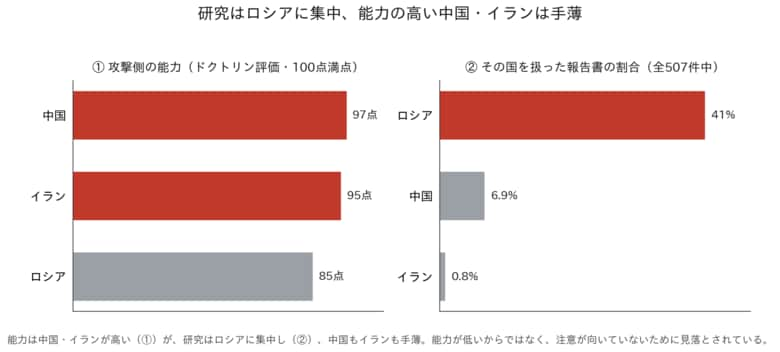
第2の発見は、攻撃能力の高い国家と、報告書が対象とした国家が、一致していなかったことである。攻撃能力の高い国家は報告書の数が少ないのだ。中国はドクトリン評価97点で最高位、報告書における評価も3か国で最も高い。
にもかかわらず、中国を対象とした件数はわずか6.9%にとどまり、ロシアの約4分の1でしかない。そのロシアはドクトリン85点で全件数の41%を占め、イランは95点に対して件数は0.8%だった。ロシアに偏りすぎている。
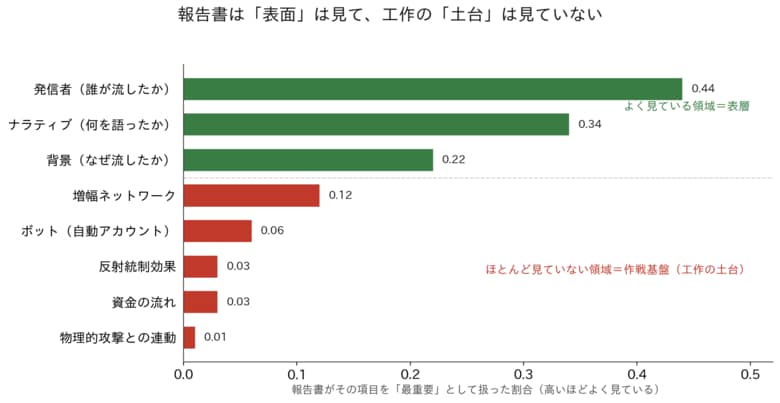
第3に、報告書がもっともよく取り上げていたのは、発信者(誰が)、ナラティブ(何を語ったか)、背景(なぜ)の3項目で安定して多くの報告書で調査分析されていた。
対象とした攻撃国ごとに死角は異なる。中国に関する報告書で際立つのはLLMグルーミングで、生成AIに関するドクトリンが最高得点であるのに、報告書の優先度はきわめて低かった。
ロシアとイランに関する報告書で際立つのはパーセプション・ハッキング(工作が暴露されること自体を利用し、社会の相互不信を煽る手法)などの反射統制効果である。攻撃側が中核に据える狙いほど、分析側では扱っていない。
上記3点から導かれるのは、欧米の認知戦分析は「暴露すること」に最適化されており、実態に即した対策を構築するためには不適という事実だ。
誰が何を語ったかは事後の暴露や犯人特定には役立つが、進行中の作戦を止めることや、被害や影響を最小限に留めることには直結しない。必要なのは、全体像を把握し、優先度を決めて行動することだ。それがそっくり抜けている。
特殊詐欺にたとえれば分かりやすい。かかってきた電話の声と手口(ナラティブと発信者)は熱心に記録するのに、金がどこへ流れ、犯罪組織の構造(作戦基盤)は追わない。
これでは受け子を一人捕まえても、本体は何事もなかったように動き続ける。いまの認知戦研究は、そういう捜査に近い。













