グラフとは何か?
「グラフ」という言葉を聞くと、折れ線グラフや棒グラフといった、いわゆる「ダイアグラム」とか「チャート」と英語で呼ばれる図表を思い浮かべる方が多いと思います。しかしここで言うグラフは、数学用語のグラフです。厳密には、以下のような定義になります
グラフGは、接点の集合Vと辺の集合Eからなる順序対であり、G = (V, E)とあらわせる。
小難しいですが、何て事はない、ただの「繋がり」、もしくは「ネットワーク」の数学の世界での呼び名にすぎません。百聞は一見に如かずで、以下の図を見ていただければ一目瞭然だと思います。

このようなネットワーク構造の事をグラフと呼びます。上の例では各頂点(ノード)はパンを焼くときに使う酵母の中に存在するたんぱく質、辺(エッジ)はそれらが直接的に相互作用を起こす事を意味しています。私の関わる生物学の分野でも、このように物質間の関係性を表したり、極めて複雑な体内での生化学的な反応を人が理解しやすくするために、それらの反応経路をグラフで表現すると言った手法が頻繁に用いられます。つまり、あらゆる経路や、人と人との関連性、相互作用といったものを解析する場合、そのデータを計算機が咀嚼できる形のグラフとして表現することは非常に重要で、それを行うことにより人間にはできないレベルの解析を行うことができるようになります。
グラフ構造というものは、文字通りあらゆるところに現れます:
・ソーシャルネットワーク
・たんぱく質間相互作用
・感染症の拡大経路
・地図
・犯罪組織の組織内構造
・恋愛関係
そしてこのようなグラフを人の目に見えるようにする事をグラフ描画と呼びます。グラフ構造は様々な分野に現れるため、この構造を解析したり描画する事そのものが研究分野になっています。特に近年、ソーシャルネットワークサービス等の普及に伴い、大規模で複雑なネットワークのデータを得やすくなったため、社会科学の分野でも様々な研究が行われています。このような研究の広がりにより、オープンソースで誰でも利用できるグラフ解析や可視化、データの蓄積に使えるソフトウェアが急速に普及しました。代表的なものでは、古い歴史を持つグラフ描画ソフトのgraphviz、Rという統計の専門家が好んで利用する統計解析用プログラミング言語実行環境の上で動くigraph、今回のケースでも利用されたソフトウェアを開発していた人が関わっていたGephi、大規模なグラフのデータを蓄積し検索できるようにするためのデータベースであるNeo4j、この記事に出てくる幾つかの私が作った図の作成にも用いられている、我々のチームが開発したCytoscapeなどがあります。ほぼすべてのものが無料で使えるため、高度なグラフ解析や可視化の技術が一般的になりつつあるというのが現在の状況です。
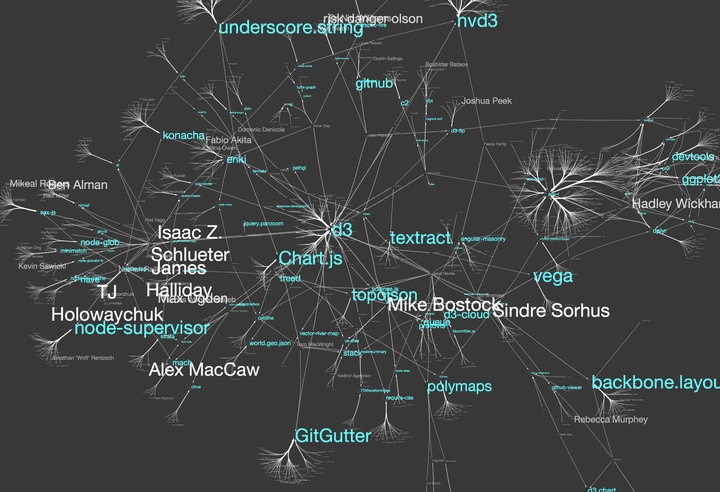
実際のグラフ構築
「機械可読なグラフデータを構築する」と書くと大変仰々しいのですが、実はそれほど複雑なことではありません。基本的に、ありとあらゆるエッジは以下の形式で表現可能です:
Node A, Edge Type, Node B
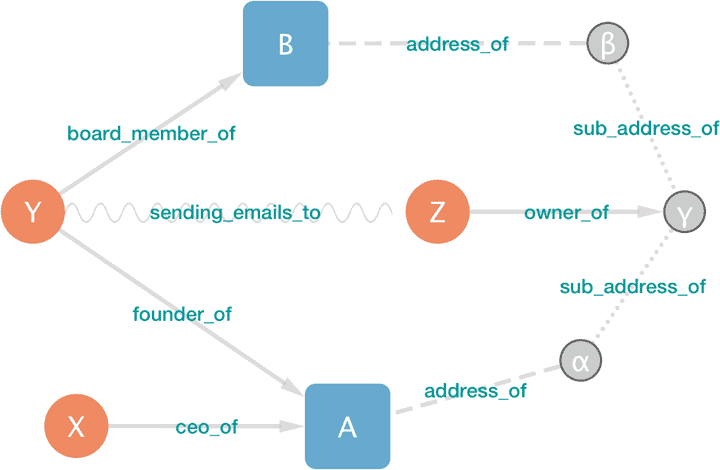
つまりこのような形のテキストで関係性を記述できれば、あらゆるグラフはデータベースや可視化ソフトで使うデータとして利用できます。具体的には、こういったグラフは単なるCSV形式のテキストテーブルとして公開されることも多いです。実際、パナマ文書より前の流出事件であるオフショア・リークス事件の時のものは、この形式でグラフデータが出回っています。どのくらい単純なものかを知っていただくために実際に作ってみましょう。データとしては前章で例として使った架空のデータである「ケイマン諸島の怪しい紳士たち」の例を使います。あの文章をグラフとして表現すると以下のような感じになります:
X ceo_of A
Y founder_of A
Y board_member_of B
Y sending_emails_to Z
α address_of A
β address_of B
α sub_address_of γ
β sub_address_of γ
Z owner_of γ
これをテキストファイルとして保存し、Cytoscapeに読み込み可視化するとこのようなものが見られます。
複雑なプロットのミステリー小説などでこのようなものを手書きで作ってあるのを目にした方も多いと思います。本質的には同じなのですが、大きな違いは、機械的にこのようなデータを作り出す仕組みを整えれば、凄まじい量のデータであってもキーワードで検索したり関係性を機械に描かせて人間が理解しやすい形にできる、という点です。今回の目的とは外れますので手法の詳細は述べませんが、このような可視化を試してみるには、テキストエディタとCytoscapeのようなオープンソースソフトウェアで簡単に行えます。今回使ったデータはここに置いておきます:
・Sample Cytoscape Session File
では、今回のデータのグラフ化はどのような作業だったのでしょうか。実際のデータが公開されていませんので、この部分の詳細は予想も混じりますが、幾つかヒントはあります。非常に小さな部分グラフですが、この記事にインタラクティブに操作できるLinkuriousの埋め込みビューアが掲載されています。
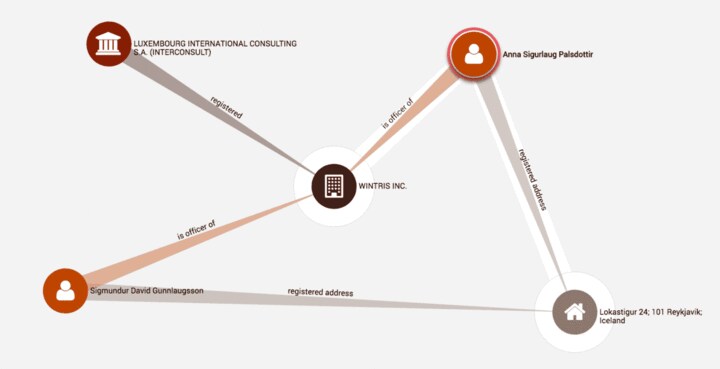
これを見る限り、ノードは以下のタイプに分類してあります
・役員名
・住所
・会社
・コンサルティング企業
そしてそれを「会社の役員である」「登録先の住所」などといった比較的単純な関係性に分類してエッジを構築しています。ここから、おそらく以下のようなことを行ったのではないかと想像しています:
・登記などからまず会社をノードとし、付随する役員、住所、担当しているコンサル会社を関連ノードとして接続
・ノードの名寄せを行い、類似の会社名、人物名などの間にも関連性ありとしてエッジを付与
・これをひたすら繰り返し、グラフをどんどん接続していく
もし公開されているサブグラフが元のデータベースのものと大差ないものであれば、比較的シンプルなデータとしてまとめた感じです。この場合、まだまだ眠っている関係性を今後掘り起こせる可能性もあります。例えば、今回はメールデータも含まれていますので、それらの差出人(From)と宛先(To)からコミュニケーションの方向性と頻度を測定し、そこからエッジのスコアに換算。これにより重み付きのエッジが大量に発生するので、より「解像度の高い」グラフデータに仕上げることも可能ではないかと思います。もちろんその先には、自然言語処理の技術を使った様々な解析もあるでしょうが、今回は触れません。なお、メールデータ等から関連人物のネットワーク構造を推定するという手法はいろいろな場面で用いられており、米国の諜報機関もテロリストのネットワークを可視化したり解析するために、類似の手法を使っていると言われています。余談ですが、過去の巨大なスキャンダルであるエンロン事件での証拠として公開されているメールのアーカイブから、関係者のネットワークを可視化すると言うプロジェクトもあります。この作者はその後スタンフォード、ワシントン大学と渡って教授となり、彼のラボからはD3.jsという非常に有名な可視化のためのライブラリが生まれました。
・exploring enron: visual data mining of e-mail by Jeffrey Heer
さて、グラフを作る方針を決めた後は、ひたすらデータの掃除と加工、データベースへの流し込みです。データ解析の世界で働いていらっしゃる方はお分かりだと思いますが、これは非常に苦痛な作業でもあります。いわゆる「データサイエンス」が実はとても泥臭い仕事だと言われる所以もこのあたりにあります。今回のデータの場合、215,000の会社組織に対し、最低3人の関係者がおり、これらのつながりをグラフ化するとおよそ100万ノードのグラフが出来上がりました。実際にNeo4jのデータベースを構築するときには、このソフトウェアを利用したようです。
http://www.talend.com/download/talend-open-studio
詳細はさらに担当者の方にインタビューをしないとわかりませんが、概ねこのような作業で、まず調査のバックボーンとなるグラフデータベースが構築されたようです。
ここまで読んで、RDBの経験者の方は「そもそもRDBのファイルでデータが流出したのならば、なんでこんなまどろっこしいことをやるのか?そのまま統合したデータベースにSQLクエリを投げれば良いのではないか?」と疑問を持たれるかもしれません。彼らがわざわざグラフ化した一番大きな理由は、経路検索などといったグラフ構造に対する特有の検索を大量に行う場合、RDBで構築したものだと使い物にならないくらいパフォーマンスが低下する場合があるからだと思います。今回の調査では、金の流れと関連人物の繋がりを見ながら資料を読み込むというユースケースだったため、グラフDBを使うのがもっとも適していると判断したのでしょう。
人海戦術のためのLinkurious
ここからは少し泥臭くなります。「データベース化したものを人工知能に自動的に解析させる」というような時代は少なくともまだ当分は来ません。ですから、ここからは人間の出番です。そもそも彼らがグラフデータベースを利用した大きな理由には、関係者のつながりを文字通り人間が見られるようにする、というグラフ可視化の機能を使いたかったという部分が大きいようです。複雑なグラフ構造を理解する場合、関係性を文章で読んでいても、とても人間の脳は大規模なものを短時間で把握することはできません。そこで彼らは構築したNeo4jデータベースをLinkuriousというグラフ可視化・解析サービスに接続しました。今回の分析には370人の世界中に散らばったジャーナリストが関わっています。これらの人々が同時に同じデータにアクセスして分散して解析作業を行って行く場合、グラフデータベースの上にそういった作業を可能とする何らかのアプリケーションを構築する必要があります。もちろんカスタムアプリケーションを自ら作ることもできるのですが、そこまでやる必要はないし、それはあまりにも負担が大きいので、Linkurious社の提供するLinkurious Enterpriseというサービスを利用したそうです。
今回参加したジャーナリストの大半は、Linkurious社が提供するアプリケーションのGUIを使って、グラフデータベースから人物と会社の関係を引き出し、それを目で確認しながら関連書類や資料を読み込んだようです。中にはNeo4jに標準搭載されているグラフクエリ用言語のCypherでより高度な検索を行いながら解析を行った高度な技術を持つユーザーもいたようです。グラフクエリ言語というのは、あるグラフに対して、特定の条件にマッチする経路やノードを検索させるためのDSL(ドメイン固有言語)の一種です。グラフを検索するための単純なプログラミング言語のようなものだと考えてもらっても概ね正しいです。単純な例で言えば、
「企業Aに2ホップ以内でつながっている人物と会社を列挙せよ」
「某国大統領とかかわりのある企業とX氏の間に経路があるか調べよ。ある場合はそれを全て列挙せよ」
といった感じの検索条件を、計算機が理解できる形の検索条件に置き換えるための言語です。こういった調査でグラフデータベースを利用する利点の一つには、構造に対するかなり複雑なクエリを実行することができる点です。経路検索はもとより、特定の小構造(ネットワークモチーフとも呼ばれます)を持った部分を探し出したりと、RDBでは難しい解析を現実的な時間で行うことができます。おそらくまだ今後も様々な解析を行っていくはずなので、続報を待ちたいところです。
技術的なポイントのまとめ
・RDBに対してリバースエンジニアリングを行い、統合された形のスキーマを抽出し検索可能にした
・AWS上に用意したOCR用のインスタンスを使い、大量のファイルをテキスト化した
・ファイルのメタデータをTikaで切り出し、テキスト化された各種書類を全文検索エンジンのApache Solrに流し込んだ。それによりキーワード検索できるようにした
・データをTalendを使い加工し、グラフ化し、Neo4jデータベースに格納した
・Neo4jのフロントエンドとしてLinkurious Enterpriseを採用した。これにより、世界中に分散したユーザーが同時に複雑なデータセットにGUIからアクセスできるようになった
今後の予想
まだ(生)データが出ていないので想像でしか物が言えないのが心苦しいですが、これらの記事を読んだ印象では、いわゆるデータサイエンティストと呼ばれる人々を迎える事により、まだまだ多面的な解析が行えそうな気がしています。
現在公開されているLinkuriousのサブグラフに出ているエッジの種類はかなり限られていますし、スコアリングや時系列の資金の流れのマッピングなどといった高度な事は行っていないようにも見えます。私は統計屋さんではないので、あくまでプログラマとしての立場の意見ですが。秘密裏にデータをシェアして共同作業を行う、という点でフロントエンドとして大きな役割を果たしたLinkuriousですが、バックエンドのNeo4jは独立して存在するので、今後グラフ構造そのものの解析や、エッジ/プロパティ追加によるデータのさらなる多面的な解析を行う場合は、直接Cypher経由で複雑なシナリオを検討する事が考えられます。また、非構造化データから抽出したキーワードや、一定のルールに基づいて行うエッジのスコアリングなどでグラフデータベースの厚みを増し、高度な解析能力を有する専門家がJupyter Notebookなどを利用したオープンで再現性のある解析を行い、ノートとデータ、できれば環境をDockerfileにまとめて、それをそのまま公開してしまう、という道もあるのではないかと思います。そうなれば解析の環境から手法、データまで含めたある意味究極の情報公開になります。
担当者の方が述べておられるように、比較的簡単で面白そうなのはスイス・リークスのデータセットとの統合です。彼らがグラフデータベースを利用し始めたのはスイス・リークスの一件の時からなので、すでにグラフデータベース化されているものがあれば、マージは比較的容易だと思われます。それによりさらに大きな俯瞰図ができれば興味深いと思います。彼女もこう言っていますし、続報を待ちましょう。
I think that we have just scratched the surface on how we can analyze the graph data.
私たちはグラフをどう解析できるのかという点について、まだ問題の表面をかすった程度の段階です。
Mar Cabra, ICIJ Data and Research Unit Editor
また、全データ公開は無理でも、ある程度加工された二次利用しやすいデータとして部分的にでも公開されれば、新聞社などのインフォグラフィックやデータビジュアライゼーションのチームが、各種公開データセット(地図など)とのマージを行って、さらに分かりやすい全体像を提示することも可能かもしれません。
おわりに
いかがでしたでしょうか。ちなみにここに列挙したツールは、Linkuriousを除き、私が可視化のサンプルを作ったCytoscapeもNeo4jも含めて全て無料で利用できます。グラフというデータ構造はこの世界のあらゆるところに現れますので、それを機械で読める形にして格納すれば、このように様々な場面で使えるとわかっていただければ幸いです。
驚くべきことに、今回の作業は全てジャーナリストの団体が行っています。彼らは内部にデータ解析班を持ち、その人々はデータの前処理のためのパイプライン作成から、商用クラウドサービスを利用した自前で計算機を持たない形でのデータ処理(おそらく多くはAWS上でのスポットインスタンス利用によるバッチ処理)、分散作業のためのシステム構築、データベースの構築、UIの選択など、ソフトウェア系の企業で行うようなことを自前でやっています。世界の調査報道の先端はここまで来ているのかと感心しました。同時に、ソフトウェアエンジニアのキャリアパスとしてこういうものも面白いのではないかとも感じました。
ビッグデータだの何だの雲をつかむようなキーワードが飛び交う昨今ですが、ここはひとつじっくりとJupyter Notebookに貴方のお気に入りのツールを組み合わせるデータ解析パイプラインを書き下し、何か社会にインパクトを与える解析・可視化作業でもしてみませんか?今は技術と知識を身につければ昔では考えられなかったレベルの作業が、オープンソースソフトウェアやクラウドサービスを利用して、個人や小さな団体でも行える時代です。これをテクノロジーの民主化と呼ぶ人もいます。
最後にNeo4j社のCEOの言葉を引用しておきます。
The democratization of technologies to make sense of data at scale is an important part of a free and open society, and I'm proud of the role we play in that evolving landscape -- not only in the case of Swiss Leaks and the Panama Papers, but in solving future problems we can't even yet imagine.
大規模データを理解するためのテクノロジーの民主化は、自由で開かれた社会の重要な一部分である。そして私はその発展を続ける情景の中で我々が担えた役割を誇りに思っている。パナマ文書やスイス・リークスに限らず、我々がまだ想像すらできない未来の問題解決のために。
Emil Eifrem, CEO, Neo Technology
CC BY 4.0
4/9/2016 Keiichiro Ono
4/10/2016 追記
この後、Neo4j社のブログに、更にテクニカルな部分について言及した記事が掲載されていました。実際にCypherを使ってグラフの構築や修正を行うとどのような感じになるのか、コードと共に書いてありますので、更にグラフデータベースの詳細に興味にある方は是非どうぞ。
・Analyzing the Panama Papers with Neo4j: Data Models, Queries & More
質問や問題点などはkono at ucsd eduまでメールでお願いします。
Some rights reserved by the author.













